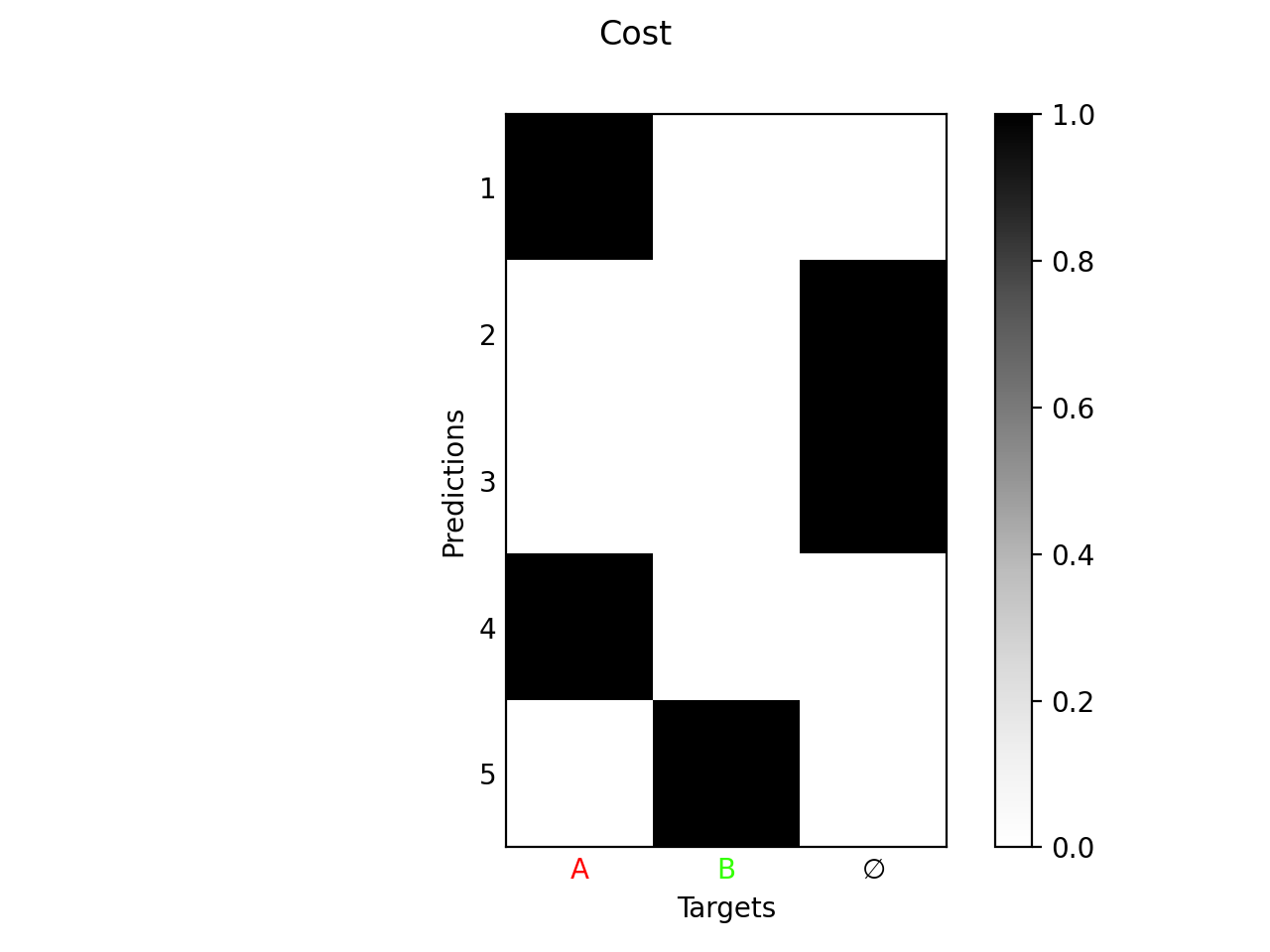
Closest Target
We consider the matching cost \(\mathcal{L}_{\text{match}}\) = cls_match_module + loc_match_module between the \(N_p\) predictions \(\hat{\mathbf{y}}_i\) and \(N_t\) targets \(\mathbf{y}_j\). In particular, the cost of the background \(\mathbf{y}_{N_t+1} = \varnothing\) is given by \(\mathcal{L}_{\text{match}}\left(\hat{\mathbf{y}}_i, \varnothing\right)\) = bg_cost.
This class computes an exact minimum over the predictions, in other words it matches each prediction to the closest target. The match \(\mathbf{P}\) is given by
For the opposite where each target is matched towards the closest prediction, we refer to uotod.match.ClosestPrediction.
Class
- class uotod.match.ClosestTarget(**kwargs)
Each prediction is matched to the closest target.
- Parameters:
cls_match_module (_Loss) – Classification loss used to compute the matching, if any.
loc_match_module (_Loss) – Localization loss used to compute the matching, if any.
background (bool, optional) – Indicates whether there is a background. Defaults to True.
background_cost (float, optional) – Cost of the background class. Defaults to 10.
is_anchor_based (bool, optional) – If True, the matching is performed between the anchor boxes and the target boxes.
- compute_cost_matrix(input: Dict[str, Tensor] | List[Dict[str, Tensor]], target: Dict[str, Tensor] | List[Dict[str, Tensor]], anchors: Tensor | None = None) Tensor
Computes a batch of cost matrices between the predicted and target boxes.
- Parameters:
input (dictionary) – Input containing the predicted logits and boxes. “pred_logits”: Tensor of shape (batch_size, num_pred, num_classes). “pred_boxes”: Tensor of shape (batch_size, num_pred, 4), where the last dimension is (x1, y1, x2, y2).
target (dictionary) – Target containing the target classes, boxes and mask. “labels”: Tensor of shape (batch_size, num_targets). “boxes”: Tensor of shape (batch_size, num_targets, 4), where the last dimension is (x1, y1, x2, y2). “mask”: Tensor of shape (batch_size, num_targets).
anchors (Tensor) – the anchors used to compute the predicted boxes. (batch_size, num_pred, 4), where the last dimension is (x1, y1, x2, y2).
background (bool, optional) – Indicated whether the background has to be added.
- Returns:
the matching between the predicted and target boxes: Tensor of shape (batch_size, num_pred, num_targets + 1) or (batch_size, num_pred, num_targets) if background is False.
- Return type:
Tensor (float)
- compute_matching(cost_matrix: Tensor, target_mask: Tensor | None) Tensor
Computes the matching.
- Parameters:
cost_matrix (Tensor) – Cost matrix of shape (batch_size, num_pred, num_targets + 1).
target_mask (BoolTensor, optional) – Target mask of shape (batch_size, num_targets).
- Returns:
The matching \(\mathbf{P}\) for each element of the batch. Tensor of shape (batch_size, num_pred, num_targets + 1). The last entry of the last dimension [:, :, num_target+1] is the background.
- forward(input: Dict[str, Tensor] | List[Dict[str, Tensor]], target: Dict[str, Tensor] | List[Dict[str, Tensor]], anchors: Tensor | None = None, cost_matrix: Tensor | None = None, save: bool = True) Tensor | Tuple[Tensor, Tensor]
Computes a batch of matchings between the predicted and target boxes.
- Parameters:
input (dictionary) – Input containing the predicted logits and boxes. “pred_logits”: Tensor of shape (batch_size, num_pred, num_classes). “pred_boxes”: Tensor of shape (batch_size, num_pred, 4), where the last dimension is (x1, y1, x2, y2).
target (dictionary) – Target containing the target classes, boxes and mask. “labels”: Tensor of shape (batch_size, num_targets). “boxes”: Tensor of shape (batch_size, num_targets, 4), where the last dimension is (x1, y1, x2, y2). “mask”: Tensor of shape (batch_size, num_targets).
anchors (Tensor) – the anchors used to compute the predicted boxes. (batch_size, num_pred, 4), where the last dimension is (x1, y1, x2, y2).
- Returns:
the matching between the predicted and target boxes, and the cost matrix if returns_cost is True: Tensor of shape (batch_size, num_pred, num_targets + 1). The last entry of the last dimension is the background.
- Return type:
Tensor (float) or Tuple(Tensor, Tensor)
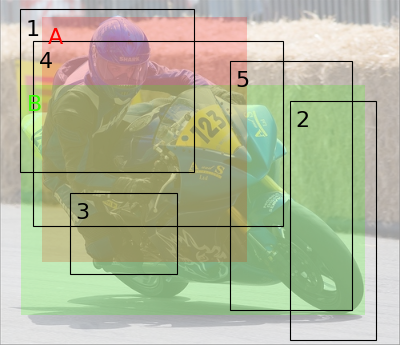
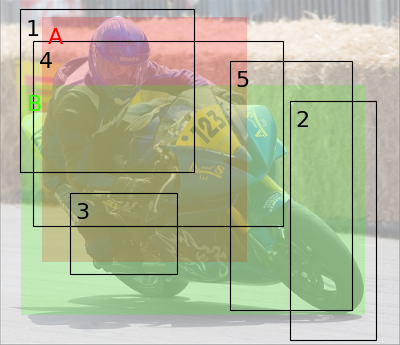
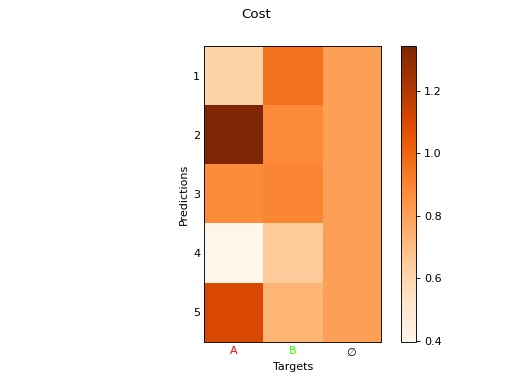
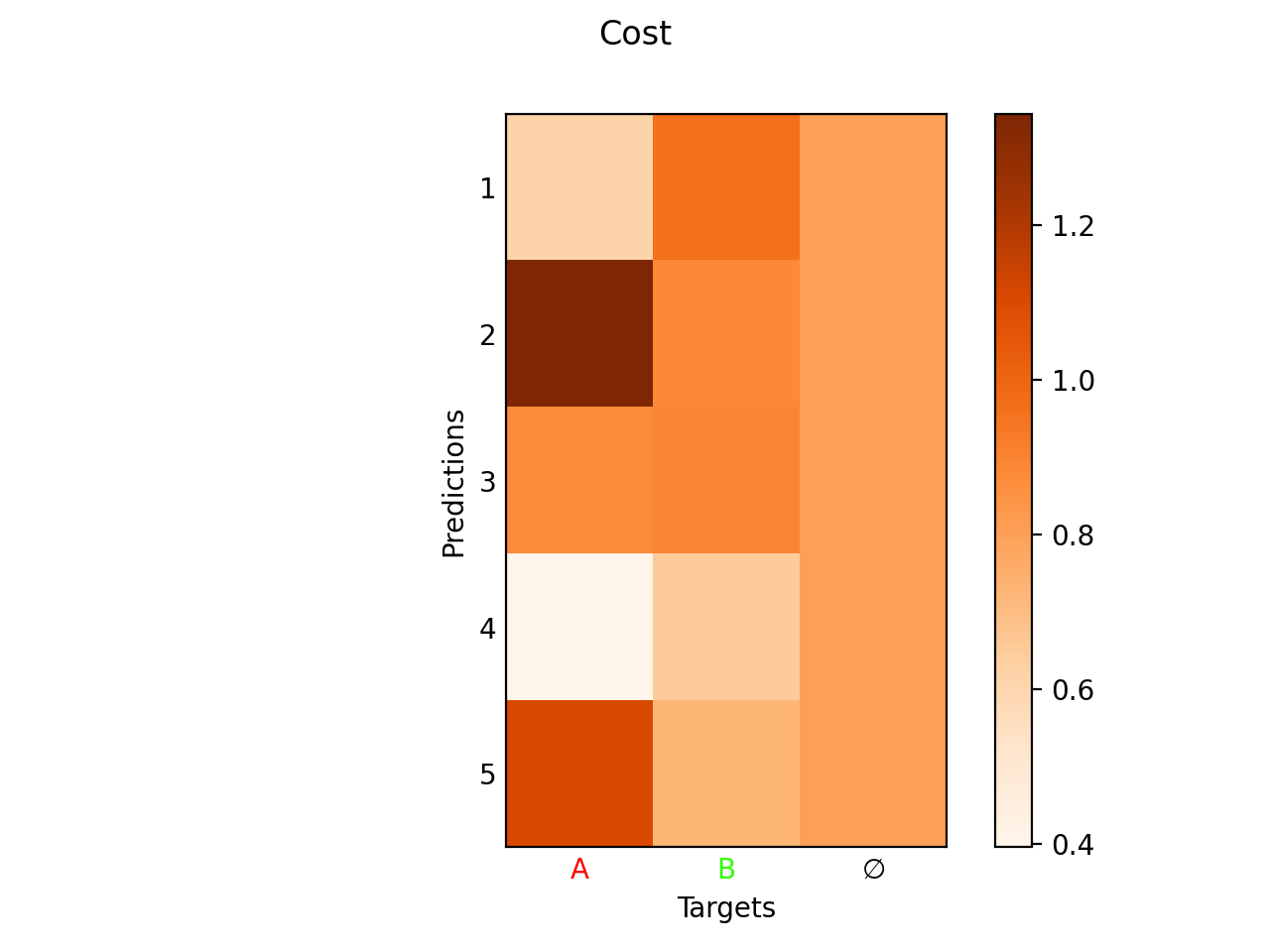
- plot(idx=0, img: Tensor | ndarray | None = None, plot_cost: bool = True, plot_match: bool = True, max_background_match: float | int = 1.0, background: bool = True, erase: bool = False)
Plots from the last batch # TODO: extensive description
- Parameters:
idx (int, optional) – Index of the image to be plotted.
img (Tensor or ndarray, optional) – Image to be plotted. If it is not None, the boxes plot is computed.
plot_cost (bool, optional) – Plots the cost matrix between the predictions and the targets, including background.
plot_match (bool, optional) – Plots the cost matrix between the predictions and the targets, including background.
max_background_match (float, optional) – A threshold to only plot relevant matched predictions. The predictions are only plotted if the value matched to the background does not exceed max_background_match. Defaults to 1.
- Returns:
Matplotlib figures
- Return type:
Tuple(fig, fig, fig)
Example
import uotod
from uotod.sample import input, target, imgs
L = uotod.loss.GIoULoss(reduction='none')
M_pred = uotod.match.ClosestTarget(loc_match_module=L, background=True, background_cost=.8)
M_pred(input, target)
fig_img, fig_cost, fig_match = M_pred.plot(idx=0, img=imgs)
fig_img.show()
fig_cost.show()
fig_match.show()
{kind=link}
{kind=link}

{kind=link}
{kind=link}

{kind=link}
{kind=link}
From the Closest Target to the Hungarian Algorithm
The module uotod.match.UnbalancedSinkhorn with low regularization can play the role of an interpolant between
uotod.match.ClosestTarget and uotod.match.Hungarian (or uotod.match.BalancedSinkhorn with the same low
regularization).
A high reg_pred will enforce a strong respect of the mass constraints on the predictions. If reg_target is
close to zero, this will emulate a minimum as the problem essentially minimizes the objective for each prediction,
disregarding the mass constraints on the targets. For a high reg_target, the problem will essentially minimize the
same objective as the uotod.match.BalancedSinkhorn, which approximates the uotod.match.Hungarian with
a low regularization. This is illustrated in the following example.
import uotod
from uotod.sample import input, target, imgs
L = uotod.loss.GIoULoss(reduction='none')
M_min_pred = uotod.match.ClosestPrediction(loc_match_module=L, background_cost=0.8)
M_unb_small = uotod.match.UnbalancedSinkhorn(loc_match_module=L, background_cost=0.8, reg=0.01, reg_pred=1.e-2, reg_target=1.e+4)
M_unb_med = uotod.match.UnbalancedSinkhorn(loc_match_module=L, background_cost=0.8, reg=0.01, reg_pred=.2, reg_target=1.e+4)
M_unb_big = uotod.match.UnbalancedSinkhorn(loc_match_module=L, background_cost=0.8, reg=0.01, reg_pred=1.e+4, reg_target=1.e+4)
M_balanced = uotod.match.BalancedSinkhorn(loc_match_module=L, background_cost=0.8, reg=0.01)
M_hungarian = uotod.match.Hungarian(loc_match_module=L, background_cost=0.8)
matches = [M_min_pred(input, target)[0, :, :],
M_unb_small(input, target)[0, :, :],
M_unb_med(input, target)[0, :, :],
M_unb_big(input, target)[0, :, :],
M_balanced(input, target)[0, :, :],
M_hungarian(input, target)[0, :, :]]
fig_matches = uotod.plot.multiple_matches(matches=matches,
subtitles=['Closest Prediction\n(min over the targets)',
'Unbalanced Sink.\n(low reg_pred)',
'Unbalanced Sink.\n(medium reg_pred)',
'Unbalanced Sink.\n(high reg_pred)',
'Balanced\nSinkhorn',
'Hungarian\nAlgorithm'],
title='Effect of reg_pred (reg=0.01)',
figsize=(20, 6))
fig_matches.show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}

When a edge case is seeked after–either uotod.match.ClosestTarget or uotod.match.Hungarian–, we encourage
to directly use these modules instead of the module uotod.match.UnbalancedSinkhorn, which is slower in
computation time. The latter should only be used when seeking for an in-between case.
Note
Similarly, when a higher regularization is used, the module uotod.match.UnbalancedSinkhorn plays the role of an
interpolant between a uotod.match.SoftMin and a uotod.match.BalancedSinkhorn with the same
regularization.
Note
The opposite case with a high reg_target will approximate uotod.match.ClosestPrediction.
Minimum over the targets
For the argument reg_pred=0, the unbalanced case uotod.match.UnbalancedSinkhorn behaves exactly the same
as the softmin uotod.match.SoftMin with the same regularization and the targets as source. Indeed no marginal
distribution has to be satisfied over the predictions. As the background cost is uniform for all predictions, the
softmin over the background \(\varnothing\) is totally uniform.
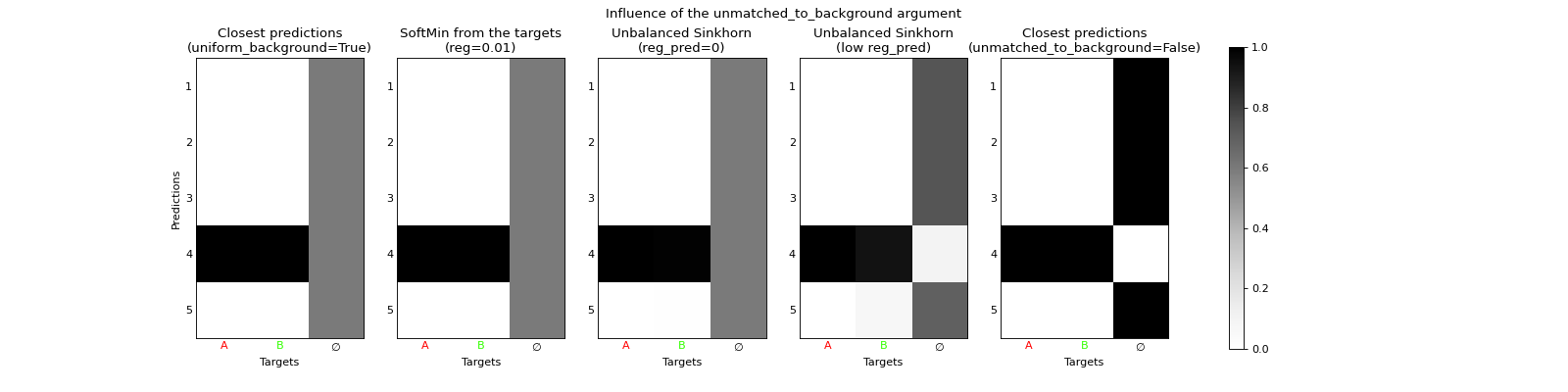
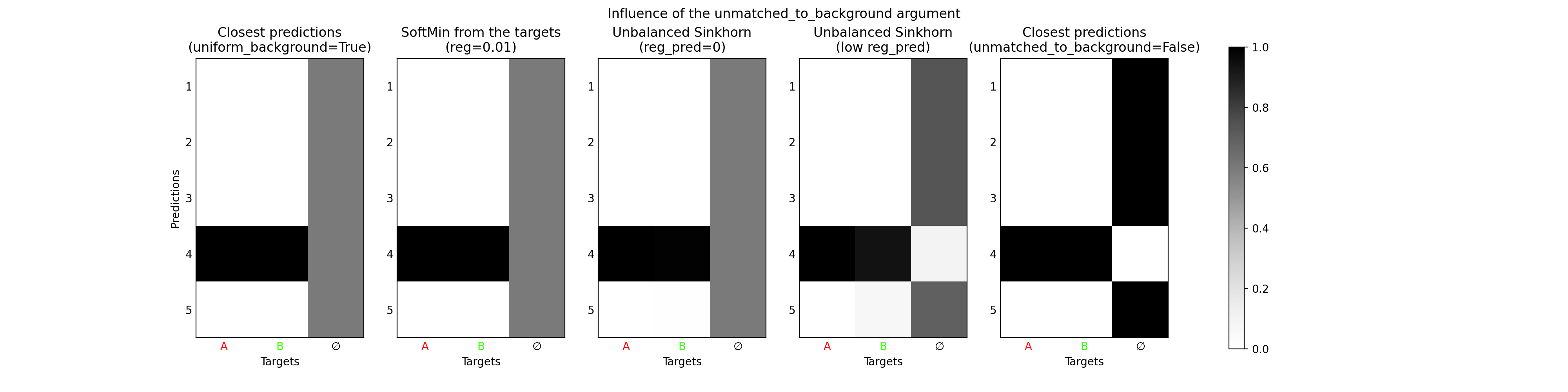
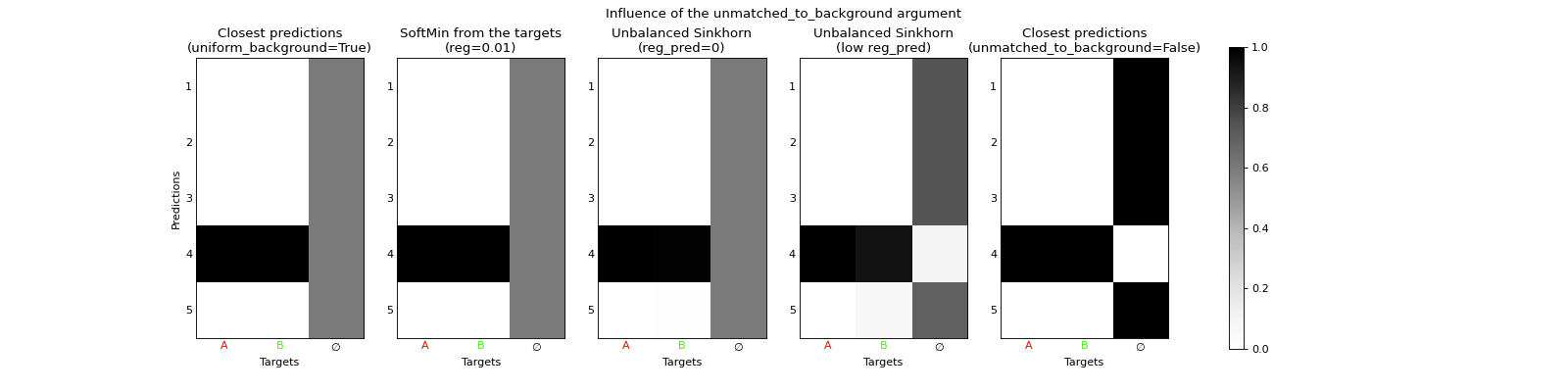
As the number of predictions is often fixed by design, but the number of actual objects to be predicted may vary for each datapoint, the background \(\varnothing\) is introduced. Its purpose is to become the output of any prediction that is irrelevant for a specific datapoint, after training. Therefore, it does not make much sense to match a prediction that is already matched to any non-background target, also to the background \(\varnothing\). In this way, the uniform result on the background obtained by the softmin or the unbalanced case with reg_pred=0 may not be very useful: it would be better to only match the unmatched predictions (to any non-background target) to the background.
This result is obtained when considering the unbalanced case with reg_pred very low instead of zero, particularly
if the entropic regularization reg is also low. When the latter tends to zero, we recover an exact minimum
uotod.match.ClosestPrediction from the targets. This justifies the argument unmatched_to_background of which the effect
can be visualized in the following example.
import uotod
from uotod.sample import input, target
L = uotod.loss.GIoULoss(reduction='none')
M_min_unif = uotod.match.ClosestPrediction(loc_match_module=L, background_cost=0.8, uniform_background=True)
M_softmin = uotod.match.SoftMin(loc_match_module=L, reg=0.01, background_cost=0.8, source='target')
M_unb_0 = uotod.match.UnbalancedSinkhorn(loc_match_module=L, background_cost=0.8, reg=0.01, reg_pred=0, reg_target=1.e+4)
M_unb_small = uotod.match.UnbalancedSinkhorn(loc_match_module=L, background_cost=0.8, reg=0.01, reg_pred=2.e-2, reg_target=1.e+4)
M_min_nonunif = uotod.match.ClosestPrediction(loc_match_module=L, background_cost=0.8, uniform_background=False)
matches = [M_min_unif(input, target)[0, :, :],
M_softmin(input, target)[0, :, :],
M_unb_0(input, target)[0, :, :],
M_unb_small(input, target)[0, :, :],
M_min_nonunif(input, target)[0, :, :]]
fig_matches = uotod.plot.multiple_matches(matches=matches,
subtitles=['Closest predictions\n(uniform_background=True)',
'SoftMin from the targets\n(reg=0.01)',
'Unbalanced Sinkhorn\n(reg_pred=0)',
'Unbalanced Sinkhorn\n(low reg_pred)',
'Closest predictions\n(unmatched_to_background=False)'],
title='Influence of the unmatched_to_background argument',
figsize=(20, 5))
fig_matches.show()
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Note
Considering the matching from the targets,
if the uniform case over the background is seeked, we strongly encourage to use uotod.match.SoftMin for
a regularized result or uotod.match.ClosestPrediction with unmatched_to_background=False for an unregularized
example. This will always run faster than uotod.match.UnbalancedSinkhorn.
If the case where only the unmatched predictions are matched towards the background is seeked, we encourage to use
uotod.match.UnbalancedSinkhorn with a non-zero, but very low reg_pred, or uotod.match.ClosestPrediction if
no entropic regularization is seeked (with the default unmatched_to_background=True). This is unattainable with
uotod.match.SoftMin.